
Reinforcement Learning via Gaussian Processes
Published:
Motivation
Estimating a value function in reinforcement learning (RL) for continuous spaces is a challenging problem. Function approximation is often used to address this challenge, with linear functions and deep learning being two popular approaches. Linear functions are interpretable but can only model simple functions, while deep learning models are powerful but can be black-box models. Gaussian process (GP) modelling is a method that offers the best of both worlds: it can model complex systems while still providing interpretable results under certain conditions. This project, focusing on Q-learning, explores the advantages and limitations of using GP in model-free RL.
Research Question
What are the advantages and limitations of Gaussian Processes as function approximators for reinforcement learning?
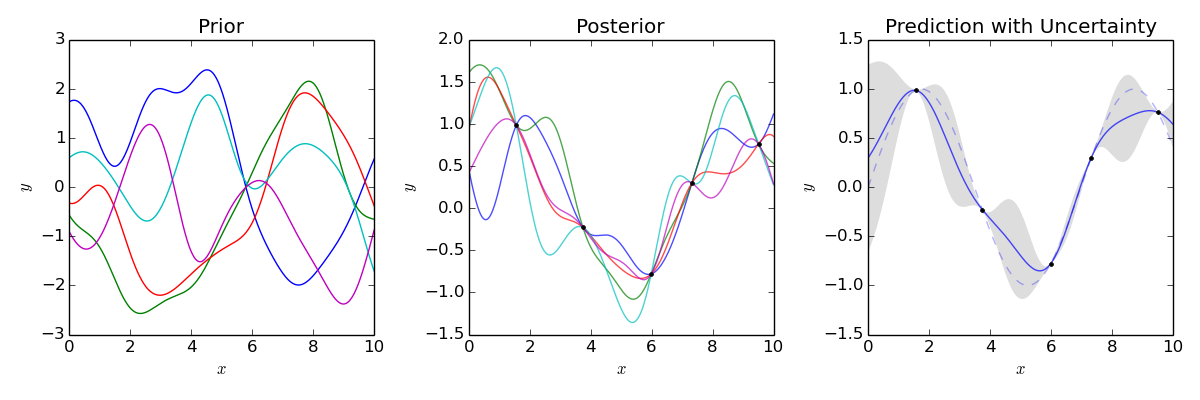
{kind=link}
Tasks and Timeline
Stage 1:
- Define the problem of interpretable function approximation in reinforcement learning.
- Delimitate the solution concept.
- Review the state-of-the-art and how GP is implemented in RL in the literature.
- Brainstorm ways to use GP in Q-learning.
Stage 2:
- Plan the experiments and test for the expected RL agent.
- Develop a Q-learning agent with GP as a function approximator.
Stage 3:
- Evaluate the agent in the proposed experiments and tests.
- Benchmark the proof-of-concept against other solutions in the literature, e.g. deep Q-learning, Q-learning via linear function approximators, and tabular Q-learning (if possible).
Stage 4:
- Document the problem description and solution-design methodology;
- Show the results to reviewers and non-technical audiences.
Expected Outcomes
Mandatory Products
- Benchmark with other reinforcement learning algorithms in the literature;
- Mathematical analysis of the proposed algorithm;
- Software with documentation associated with the project;
- Technical report with problem description, proposed solutions, experimental results, and project conclusions by following the University guidelines;
- A public dissertation following the University guidelines.
Optional Products
- Summary paper from the technical report suitable for conferences or journals;
- 3-minute elevator pitch video of the project;
- Blog post or video explaining the problem and proposed solution for a general audience.
Bibliography
- Srinivas, N., Krause, A., Kakade, S. M., & Seeger, M. (2009). Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv preprint arXiv:0912.3995.
- Section 2 in Berkenkamp, F. (2019). Safe exploration in reinforcement learning: Theory and applications in robotics (Doctoral dissertation, ETH Zurich).